Nature Knows and Psionic Success
God provides
Brain-inspired AI inspires insights about the brain (and vice versa)
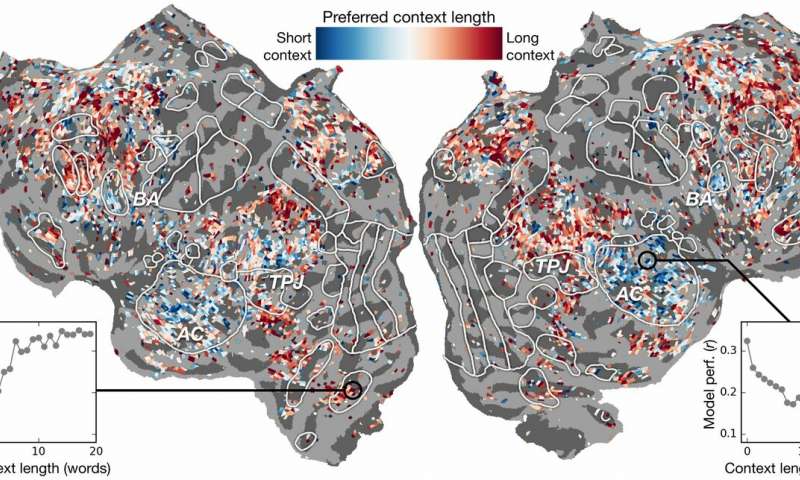
Context length preference across cortex. An index of context length preference is computed for each voxel in one subject and projected onto that subject’s cortical surface. Voxels shown in blue are best modeled using short context, while red voxels are best modeled with long context. Credit: Huth lab, UT Austin Can artificial intelligence (AI) help us understand how the brain understands language? Can neuroscience help us understand why AI and neural networks are effective at predicting human perception? Research from Alexander Huth and Shailee Jain from The University of Texas at Austin (UT Austin) suggests both are possible. In a paper presented at the 2018 Conference on Neural Information Processing Systems (NeurIPS), the scholars described the results of experiments that used artificial neural networks to predict with greater accuracy than ever before how different areas in the brain respond to specific words. "As words come into our heads, we form ideas of what someone is saying to us, and we want to understand how that comes to us inside the brain," said Huth, assistant professor of Neuroscience and Computer Science at UT Austin. "It seems like there should be systems to it, but practically, that’s just not how language works. Like anything in biology, it’s very hard to reduce down to a simple set of equations." The work employed a type of recurrent neural network called long short-term memory (LSTM) that includes in its calculations the relationships of each word to what came before to better preserve context. "If a word has multiple meanings, you infer the meaning of that word for that particular sentence depending on what was said earlier," said Jain, a Ph.D. student in Huth’s lab at UT Austin. "Our hypothesis is that this would lead to better predictions of brain activity because the brain cares […]
Click here to view full article

The Power Within by Corey Daniels book available for only $2.99
Mind has both conscious and subconscious halves. These are likened to a driver and the truck he drives. The driver plans the destination and observes road conditions, while the truck provides motive power. Your subconscious mind is like the truck and it only goes in the direction in which is a steered. This can be the road or off a cliff. Likewise, the consciousness paints a picture of what the world is and what your goals are and the subconscious acts on them through emotion, physical response and energy, whether these are correct, rational images or false negative ones. The subconscious is also like an emotional reservoir which your body and mind draw responses from to external stimuli.
The Power Within lays out a method of programming your subconscious and tapping into the Holy Spirit, God voice or what the Greeks called the daimon (godman).