Nature Knows and Psionic Success
God provides
Privacy Attacks on Machine Learning Models
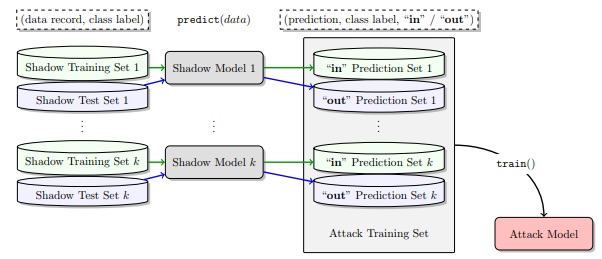
Machine Learning Models, just like most software, can be hacked Privacy attacks against machine learning systems, such as membership inference attacks and model inversion attacks, can expose personal or sensitive information Several attacks do not require direct access to the model but can be used versus the model API Personalized models, such as predictive text, can expose highly sensitive information Sensitive training data and their models should be secured Machine learning is an exciting field of new opportunities and applications; but like most technology, there are also dangers present as we expand the machine learning systems and reach within our organizations. The use of machine learning on sensitive information, such as financial data, shopping histories, conversations with friends and health-related data, has expanded in the past five years — and so has the research on vulnerabilities within those machine learning systems. In the news and commentary today, the most common example of hacking a machine learning system is adversarial input. Adversarial input, like the video shown below, are crafted examples which fool a machine learning system into making a false prediction. In this video, a group of researchers at MIT were able to show that they can 3D print an adversarial turtle which is misclassified as a rifle from multiple angles by a computer vision system. In general, adversarial examples are used to confuse the decision or outcome of a machine learning system in order to achieve some goal. This could be a simple misclassification of an example or a targeted account. This has been covered again and again in the press; does pose significant security threats to things like self-driving cars. However, an often overlooked danger within machine learning is the research on privacy attacks against machine learning systems. In this article, we’ll explore several privacy attacks which […]
Click here to view full article

The Power Within by Corey Daniels book available for only $2.99
Mind has both conscious and subconscious halves. These are likened to a driver and the truck he drives. The driver plans the destination and observes road conditions, while the truck provides motive power. Your subconscious mind is like the truck and it only goes in the direction in which is a steered. This can be the road or off a cliff. Likewise, the consciousness paints a picture of what the world is and what your goals are and the subconscious acts on them through emotion, physical response and energy, whether these are correct, rational images or false negative ones. The subconscious is also like an emotional reservoir which your body and mind draw responses from to external stimuli.
The Power Within lays out a method of programming your subconscious and tapping into the Holy Spirit, God voice or what the Greeks called the daimon (godman).