Nature Knows and Psionic Success
God provides
Deep learning rises: New methods for detecting malicious PowerShell
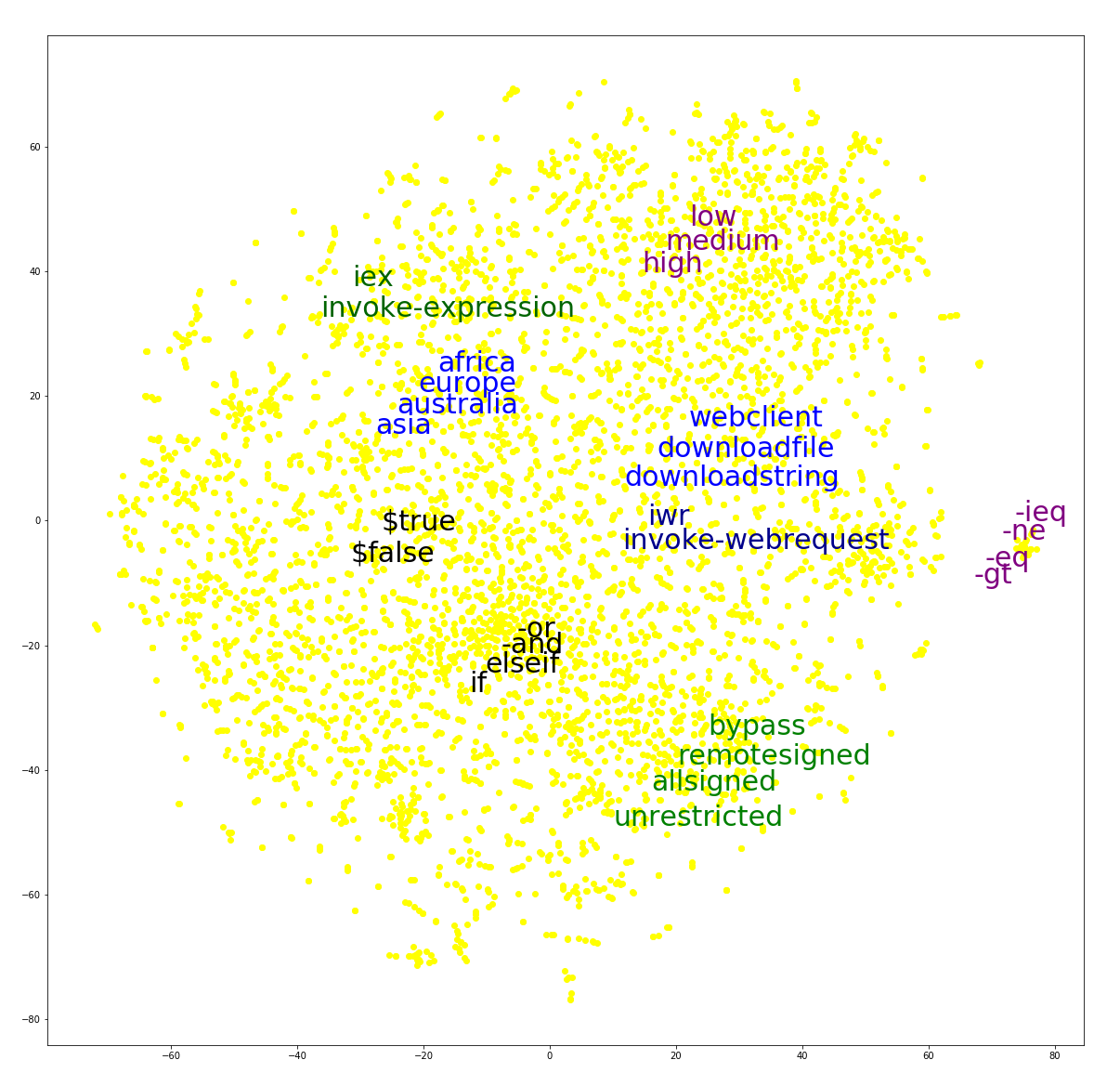
Scientific and technological advancements in deep learning, a category of algorithms within the larger framework of machine learning, provide new opportunities for development of state-of-the art protection technologies. Deep learning methods are impressively outperforming traditional methods on such tasks as image and text classification. With these developments, there’s great potential for building novel threat detection methods using deep learning. Machine learning algorithms work with numbers, so objects like images, documents, or emails are converted into numerical form through a step called feature engineering , which, in traditional machine learning methods, requires a significant amount of human effort. With deep learning, algorithms can operate on relatively raw data and extract features without human intervention. At Microsoft, we make significant investments in pioneering machine learning that inform our security solutions with actionable knowledge through data, helping deliver intelligent, accurate, and real-time protection against a wide range of threats. In this blog, we present an example of a deep learning technique that was initially developed for natural language processing (NLP) and now adopted and applied to expand our coverage of detecting malicious PowerShell scripts, which continue to be a critical attack vector . These deep learning-based detections add to the industry-leading endpoint detection and response capabilities in Microsoft Defender Advanced Threat Protection ( Microsoft Defender ATP ). Word embedding in natural language processing Keeping in mind that our goal is to classify PowerShell scripts, we briefly look at how text classification is approached in the domain of natural language processing. An important step is to convert words to vectors (tuples of numbers) that can be consumed by machine learning algorithms. A basic approach, known as one-hot encoding , first assigns a unique integer to each word in the vocabulary, then represents each word as a vector of 0s, with 1 at the […]
Click here to view full article

The Power Within by Corey Daniels book available for only $2.99
Mind has both conscious and subconscious halves. These are likened to a driver and the truck he drives. The driver plans the destination and observes road conditions, while the truck provides motive power. Your subconscious mind is like the truck and it only goes in the direction in which is a steered. This can be the road or off a cliff. Likewise, the consciousness paints a picture of what the world is and what your goals are and the subconscious acts on them through emotion, physical response and energy, whether these are correct, rational images or false negative ones. The subconscious is also like an emotional reservoir which your body and mind draw responses from to external stimuli.
The Power Within lays out a method of programming your subconscious and tapping into the Holy Spirit, God voice or what the Greeks called the daimon (godman).