Nature Knows and Psionic Success
God provides
The 10 Algorithms every Machine Learning Engineer should know
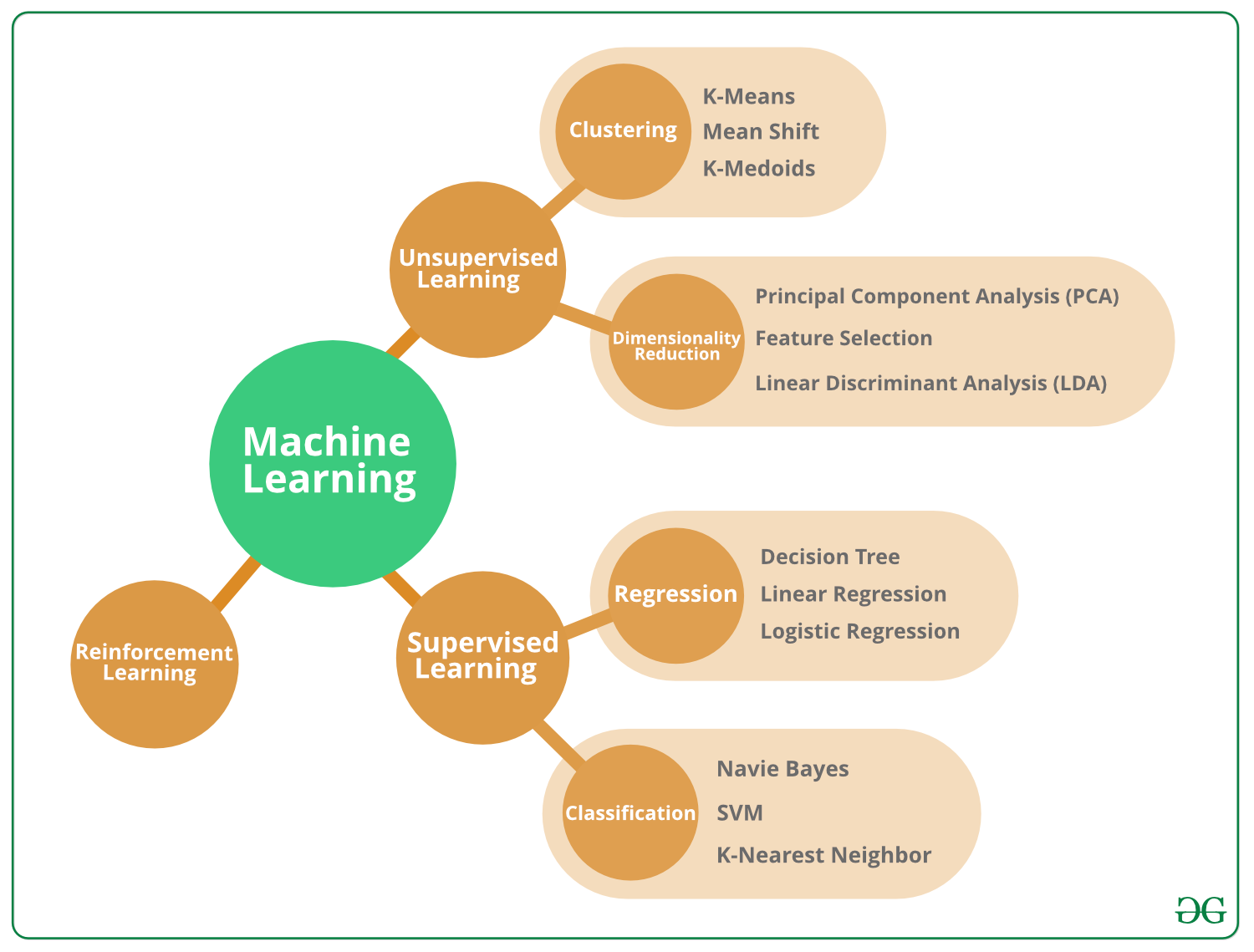
“ Computers are able to see, hear and learn. Welcome to the future. ” And Machine Learning is the future. According to Forbes , Machine learning patents grew at a 34% Rate between 2013 and 2017 and this is only set to increase in coming times. Moreover, a Harvard Business review article called a Data Scientist as the “Sexiest Job of the 21st Century” (And that’s incentive right there!!!). In these highly dynamic times, there are various machine learning algorithms developed to solve complex real-world problems. These algorithms are highly automated and self-modifying as they continue to improve over time with the addition of an increased amount of data and with minimum human intervention required. So this article deals with the Top 10 Machine Learning algorithms . But to understand these algorithms, first, the different types they can belong to are explained briefly. Machine Learning algorithms can be classified into 3 different types, namely: Supervised Machine Learning Algorithms: Imagine a teacher supervising a class. The teacher already knows the correct answers but the learning process doesn’t stop until the students learn the answers as well (poor kids!). This is the essence of Supervised Machine Learning Algorithms. Here, the algorithm is the student that learns from a training dataset and makes predictions that are corrected by the teacher. This learning process continues until the algorithm achieves the required level of performance. Unsupervised Machine Learning Algorithms: In this case, there is no teacher for the class and the poor students are left to learn for themselves! This means that for Unsupervised Machine Learning Algorithms, there is no specific answer to be learned and there is no teacher. The algorithm is left unsupervised to find the underlying structure in the data in order to learn more and more about the data itself. […]
Click here to view full article

The Power Within by Corey Daniels book available for only $2.99
Mind has both conscious and subconscious halves. These are likened to a driver and the truck he drives. The driver plans the destination and observes road conditions, while the truck provides motive power. Your subconscious mind is like the truck and it only goes in the direction in which is a steered. This can be the road or off a cliff. Likewise, the consciousness paints a picture of what the world is and what your goals are and the subconscious acts on them through emotion, physical response and energy, whether these are correct, rational images or false negative ones. The subconscious is also like an emotional reservoir which your body and mind draw responses from to external stimuli.
The Power Within lays out a method of programming your subconscious and tapping into the Holy Spirit, God voice or what the Greeks called the daimon (godman).